
파이썬으로 시험을 보기 전에 기본 문법은 확실히 정리하고 보자.
round()
IEEE754 표준에서는 실수형을 저장하기 위해 4바이트, 8바이트라는 고정된 크기의 메모리를 할당하기 때문에 현대 컴퓨터 시스템은 대체로 실수 정보를 표현하는 정확도에 한계를 가진다.
파이썬에서도 0.3 + 0.6을 출력해보면 0.89999999999999가 출력된다.
round() 함수는 소수점 특정 자릿수에서 반올림을 해준다. 코테에서는 흔히 소수점 다섯 번째 자리에서 반올림한 결과가 같으면 정답으로 인정하는 식이다. round() 함수는 두 번째 인자로 (반올림하고자 하는 위치 - 1)을 넘겨줘야 한다.
a = 0.3 + 0.6
print(round(a,4))
리스트 자료형
리스트 관련 메서드

insert() 함수와 remove() 메서드의 시간 복잡도는 O(N)이다. 그러므로 이를 남발하면 시간 초과가 뜰 수 있으니 조심하자.
특정한 원소의 값을 제거하려면 집합(set)을 만들어서 원소를 하나씩 확인하면서 remove_set에 없으면 result에 넣어주면 된다.
a = [1,2,3,4,5,5,5]
remove_set = {3,5}
result = [i for i in a if i not in remove_set]
print(result)
문자열 자료형
문자열 초기화
문자열 안에 큰따옴표나 작은따옴표를 포함할 때는 백 슬래시(\)를 이용하면 된다.
data = 'Hello World'
print(data)
data = "Don't you know \"Python\"?"
print(data)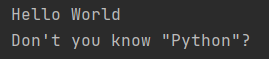
문자열 연산
파이썬은 덧셈을 이용하면 문자열을 이어 붙일 수 있다. 또한 문자열 변수를 양의 정수와 곱하면, 그 값만큼 여러 번 더해진다.
파이썬의 문자열은 내부적으로 리스트와 같이 처리되기 때문에 슬라이싱과 인덱싱을 이용할 수 있다.
a = "Hello"
b = "World"
print(a + " " + b)
a = "String"
print(a*3)
a = "ABCDEF"
print(a[2:5])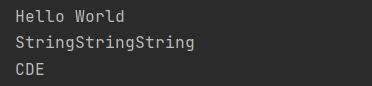
튜플 자료형
튜플은 리스트와 거의 비슷하지만 다음과 같은 차이점이 있다.
- 튜플은 한번 선언된 값을 변경할 수 없다.
- 튜플은 소괄호(())를 이용한다.
대입 연산자(=)를 사용하여 값을 변경할 수 없다.
튜플은 그래프 알고리즘을 구현할 때 자주 사용된다. 최단 경로 알고리즘인 다익스트라 알고리즘의 내부에서는 우선순위 큐를 이용하는데 해당 알고리즘에서 우선순위 큐에 한 번 들어간 값은 변경되지 않기 때문에 튜플을 사용한다.
변경하면 안 되는 값을 변경하고 있는지 확인할 수 있다. 또한 리스트에 비해 상대적으로 공간 효율적이고, 일반적으로 각 원소의 성질이 서로 다를 때 사용한다. 최단 경로 알고리즘에서 튜플을 (비용, 노드 번호)로 사용하는 것처럼 말이다.
사전 자료형
사전 자료형의 가장 큰 특징은 키(Key)와 값(Value)을 가진다는 것이다. 또한 변경 불가능한 데이터를 키로 사용할 수 있다.
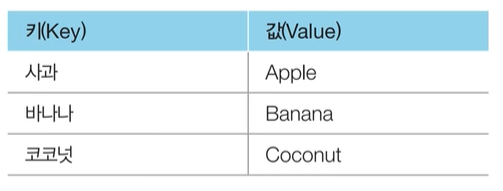
파이썬의 사전 자료형은 내부적으로 해시 테이블(Hash Table)을 이용하기 때문에 데이터의 검색 및 수정을 O(1)의 시간에 처리할 수 있다.
딕셔너리의 Key값만 뽑고 싶으면 keys() 메서드를, Value값만 뽑고싶으면 values()를 사용하면 된다.
집합 자료형
집합(set)의 가장 큰 특징은 아래와 같다.
- 중복을 허용하지 않는다.
- 순서가 없다.
리스트나 튜플은 순서가 있기 때문에 인덱싱을 통해 자료형의 값을 얻을 수 있었다. 반면에 사전 자료형과 집합 자료형은 순서가 없기 때문에 인덱싱으로 값을 얻을 수 없다.
집합 자료형은 Key값이 없고 Value만 있다. 특정 데이터 검색 및 수정의 시간 복잡도는 사전 자료형과 같이 O(1)이다.
집합을 초기화하는 방법은 아래와 같이 두 가지 방법이 있다.
data = set([1,1,2,3,4,4,5])
print(data)
data = {1,1,2,3,4,4,5}
print(data)
집합 자료형의 연산
집합 자료형의 연산으로는 합집합, 교집합, 차집합이 있는데, 합집합은 '|', 교집합은 '&', 차집합은 '-'을 이용한다.
a = {1,2,3,4,5}
b = {3,4,5,6,7}
print(a|b)
print(a&b)
print(a-b)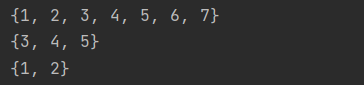
집합 자료형 관련 함수
add() 함수는 집합 데이터에 값을 추가해준다. -> O(1)
update() 함수는 여러 개의 값을 한꺼번에 추가해준다.
remove() 함수는 특정한 값을 제거할 때 사용한다. -> O(1)
data = set([1,2,3])
print(data)
data.add(4)
print(data)
data.update([5,6])
print(data)
data.remove(3)
print(data)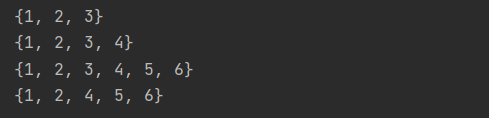
입출력
sys.stdin.readline()
입력만으로 시간 초과가 뜰 경우 input()을 대신해서 사용하는 sys.stdin.readline()은 뒤에 rstrip()을 써줘야 입력 후의 '엔터'가 제거된다.
f-string
f-string을 이용하면 중괄호 안에 변수를 넣음으로써 자료형의 변환 없이 문자열과 정수를 함께 넣을 수 있다.
answer = 7
print(f"정답은 {answer} 입니다")
주요 라이브러리의 문법과 유의점
표준 라이브러리
표준 라이브러리란 특정한 프로그래밍 언어에서 자주 사용되는 표준 소스코드를 미리 구현해 놓은 라이브러리이다.
https://docs.python.org/ko/3/library/index.html 에서 표준 라이브러리를 확인할 수 있다.
굉장히 많은 라이브러리들이 있지만 반드시 알아야 하는 라이브러리는 6가지 정도이다.
- 내장 함수: print(), input()과 같은 기본 입출력 기능부터 sorted()와 같은 정렬 기능을 포함하고 있는 기본 내장 라이브러리이다(import 필요 없음).
- itertools: 파이썬에서 반복되는 형태의 데이터를 처리하는 기능을 제공하는 라이브러리이다. 순열과 조합 라이브러리를 제공한다.
- heapq: 힙(Heap) 기능을 제공하는 라이브러리이다. 우선순위 큐 기능을 구현하기 위해 사용한다.
- bisect: 이진 탐색(Binary Search) 기능을 제공하는 라이브러리이다.
- collections: 덱(deque), 카운터(Counter) 등의 자료구조를 포함하고 있다.
- math: 필수적인 수학적 기능을 제공한다. 팩토리얼, 제곱근, 최대공약수(GCD), 삼각함수 관련 함수부터 파이(pi)와 같은 상수를 포함하고 있다.
내장 함수
result = sum([1,2,3,4,5])
print(result)
result = eval("(3+5)*7")
print(result)
result = sorted([9,1,8,5,4])
print(result)
result = sorted([9,1,8,5,4],reverse=True)
print(result)
result = sorted([('홍길동',35),('이순신',75),('아무개',50)],
key=lambda x:x[1],reverse=True)
print(result)
data = [9,1,8,5,4]
data.sort()
print(data)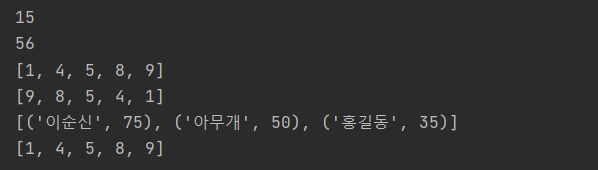
sum() 함수는 리스트와 같은 iterable 객체가 입력으로 주어지면, 합을 반환해준다.
eval() 함수는 수학 수식이 문자열 형식으로 들어오면 해당 수식을 계산한 결과를 반환한다.
itertools
itertools에서 가장 유용하게 사용할 수 있는 클래스는 permutations, combinations이다. permutations는 iterable 객체에서 r개의 데이터를 뽑아 일렬로 나열하는 모든 경우(순열)를 계산해준다.
from itertools import permutations
data = ['A','B','C']
result = list(permutations(data,3))
print(result)
combinations는 r개의 데이터를 뽑아 순서를 고려하지 않고 나열하는 모든 경우(조합)를 계산한다.
from itertools import combinations
data = ['A','B','C']
result = list(combinations(data,2))
print(result)
product는 중복을 포함하여 permutations를 실행해준다. 객체를 초기화할 때는 뽑고자 하는 데이터 수를 repeat 속성 값으로 넘겨준다. permutations와 마찬가지로 product는 클래스이므로 객체 초기화 이후에는 리스트 자료형으로 변환하여 사용한다.
from itertools import product
data = ['A','B','C']
result = list(product(data,repeat=2))
print(result)
combinations_with_replacement는 combinations와 같지만 원소를 중복해서 뽑는다.
from itertools import combinations_with_replacement
data = ['A','B','C']
result = list(combinations_with_replacement(data,2))
print(result)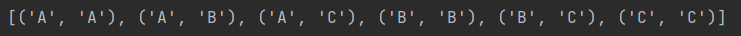
heapq
heapq 라이브러리는 다익스트라 최단 경로 알고리즘을 포함해 다양한 알고리즘에서 우선순위 큐 기능을 구현하고자 할 때 사용된다. heapq 외에도 PriorityQueue 라이브러리를 사용할 수 있지만, 코딩 테스트 환경에서는 보통 heapq가 더 빠르게 동작한다고 한다.
또한 파이썬에서의 heap은 최소 힙이다.
힙에 원소를 삽입할 때는 heapq.heappush() 메서드를, 꺼낼 때는 heapq.heappop() 메서드를 이용한다.
import heapq
def heapsort(iterable):
h = []
result = []
for value in iterable:
heapq.heappush(h, value)
for i in range(len(h)):
result.append(heapq.heappop(h))
return result
result = heapsort([1,3,5,7,9,2,4,6,8,0])
print(result)
파이썬은 최대 힙을 제공하지 않기 때문에 음수로 바꾸어서 최소 힙에 넣은 뒤 꺼낼 때 다시 음수를 취해주어야 한다.
import heapq
def heapsort(iterable):
h = []
result = []
for value in iterable:
heapq.heappush(h, -value)
for i in range(len(h)):
result.append(-heapq.heappop(h))
return result
result = heapsort([1,3,5,7,9,2,4,6,8,0])
print(result)
bisect
bisect 라이브러리는 정렬된 배열에서 특정한 원소를 찾아야 할 때 매우 효과적이다.
- bisect_left(a, x): 정렬된 순서를 유지하면서 리스트 a에 데이터 x를 삽입할 가장 왼쪽 인덱스를 찾는다.
- bisect_right(a, x): 정렬된 순서를 유지하면서 리스트 a에 데이터 x를 삽입할 가장 오른쪽 인덱스를 찾는다.
from bisect import bisect_left, bisect_right
a = [1,2,4,4,8]
x = 4
print(bisect_left(a,x))
print(bisect_right(a,x))
'삽입'할 인덱스이기 때문에 bisect_left는 2를, bisect_right는 4를 반환한 것이다.
또한 이 두 함수는 정렬된 리스트에서 값이 특정 범위에 속하는 원소의 개수를 구할 때 효과적이다.
아래의 count_by_range(a, left_value, right_value) 함수는 정렬된 리스트에서 값이 [left_value, right_value]에 속하는 데이터의 개수를 반환한다.
from bisect import bisect_left, bisect_right
def count_by_range(a, left_value, right_value):
right_index = bisect_right(a,right_value)
left_index = bisect_left(a,left_value)
return right_index - left_index
a = [1,2,3,3,3,3,4,4,8,9]
print(count_by_range(a,4,4))
print(count_by_range(a,-1,3))
collections
collections 라이브러리는 deque와 Counter 클래스를 제공한다.
보통 파이썬에서는 별도로 제공되는 Queue 라이브러리가 있지만 일반적인 큐 자료구조를 구현하는 라이브러리가 아니다. 그러므로 deque를 이용해서 큐를 구현해야 한다.
아래 표는 시간 복잡도에 있어서 리스트와 deque를 비교한 것이다.
| 리스트 | deque | |
| 가장 앞쪽에 원소 추가 | O(N) | O(1) |
| 가장 뒤쪽에 원소 추가 | O(1) | O(1) |
| 가장 앞쪽에 있는 원소 제거 | O(N) | O(1) |
| 가장 뒤쪽에 있는 원소 제거 | O(1) | O(1) |
deque는 첫 번째 원소를 삭제할 때는 popleft()를, 삽입할 때는 appendleft(x)를 사용하면 된다.
또한 마지막 원소를 삽입, 삭제할 때는 일반 리스트와 같이 append()와 pop()을 사용하면 된다.
from collections import deque
data = deque([2,3,4])
data.appendleft(1)
data.append(5)
print(data)
print(list(data))
Counter는 등장 횟수를 세는 기능을 제공한다. iterable 객체가 주어졌을 때, 해당 객체 내부의 원소가 몇 번씩 등장했는지를 알려준다.
from collections import Counter
counter = Counter(['red','blue','red','green','blue','blue'])
print(counter['blue'])
print(counter['green'])
print(dict(counter))
사전 자료형으로 변환하면 3번째처럼 출력된다.
math
math 라이브러리는 수학 계산을 요구하는 문제가 나오면 사용할 수 있다.
- factorial(x) : x! 반환
- sqrt(x) : √x 반환
- gcd(a, b) : a와 b의 최대 공약수 반환
- pi : 파이(pi) 반환
- e : 자연상수(e) 반환
이코테 외 파이썬 문법들
ord(문자)
문자에 해당하는 유니코드 정수를 반환한다.
ord('a') -> 97
chr(정수)
정수에 해당하는 유니코드 문자를 반환합니다.
chr(97) -> 'a'
사용 예시 (입력 알파벳이 몇 번째 알파벳인지 확인하기)
alphabet = input()
rank = int(ord(alphabet)) - int(ord('a')) + 1
print(rank)ord('a')를 빼주면 구할 수 있다.