
그래프 (Graph)
그래프는 노드(Node 혹은 정점(Vertex))와 간선(Edge)으로 표현된다.
그래프 탐색이란 하나의 정점으로부터 다른 노드들을 방문하는 것을 말한다. 또한 두 노드가 간선으로 연결되어 있다면 "두 노드는 인접하다(Adjacent)" 라고 말한다.
인접 행렬 (Adjacency Matrix)
인접 행렬은 2차원 배열로 그래프의 연결 관계를 표현하는 방식이다.
이 때 연결이 되어있지 않은 노드끼리는 무한대의 비용이라고 생각한다. 실제 코드에서는 논리적으로 정답이 될 수 없는 큰 값들을 999999999 등의 값으로 초기화하는 경우가 많다.
INF = 999999999 #무한의 비용 선언
# 인접 행렬 구현
grpah = [
[0, 7, 5],
[7, 0, INF],
[5, INF, 0]
]
print(graph)위의 예시에서 graph[0][1] == 7인데, 이 뜻은 0번 노드와 1번 노드가 7의 비용으로 연결되어있다는 뜻이다. 또한 i=j 대각선을 기준으로 대칭이기 때문에 무방향 그래프이다.
인접 리스트 (Adjacency List)
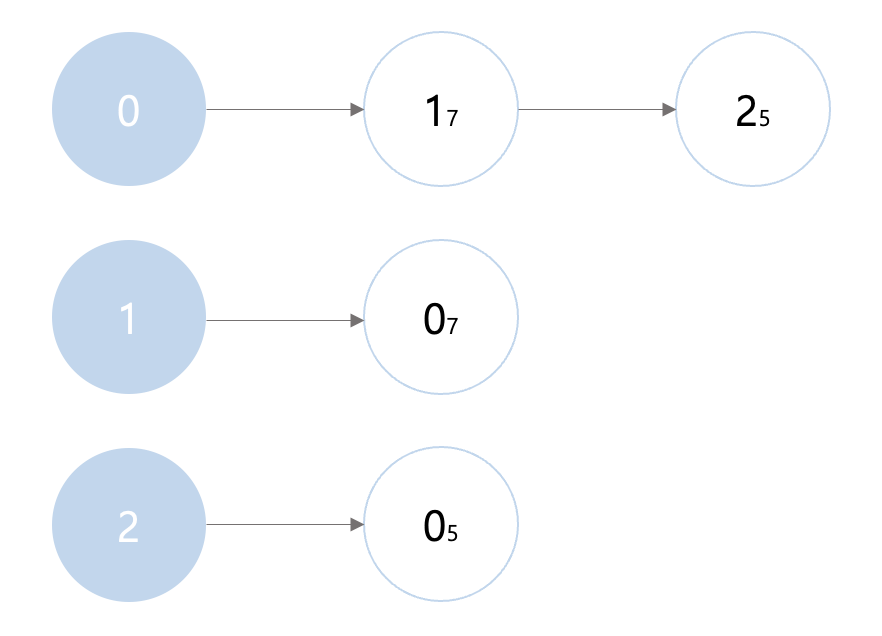
인접 리스트는 연결 리스트라는 자료구조를 이용해서 구현하는데, C++이나 자바에서는 별도로 연결 리스트 기능을 위한 표준 라이브러리를 제공한다.
반면에 파이썬은 기본 자료형인 리스트 자료형이 append() 메서드를 제공하기 때문에 배열과 연결리스트의 기능을 모두 기본으로 제공한다 (즉 라이브러리를 import할 필요가 없고 2차원 배열을 이용하면 된다).
graph = [[] for _ in range(3)]
graph[0].append((1, 7))
graph[0].append((2, 5))
graph[1].append((0, 7))
graph[2].append((0, 5))
print(graph)
# [[(1, 7), (2, 5)], [(0, 7)], [(0, 5)]]graph[0]은 튜플 (1,7)과 (2,5)가 연결되어 있는데 첫 번째 수는 노드 이름, 두 번째 수는 비용이다.
두 방식의 차이점
메모리 측면에서 보면 인접 행렬 방식은 모든 관계를 저장하기 때문에 노드 개수가 많을수록 불필요한 메모리가 늘어난다. 반면에 인접 리스트 방식은 연결된 정보만을 저장하기 때문에 낭비되는 메모리가 없다.
속도 측면에서 보면 인접 행렬 방식은 두 노드가 연결되어 있는지에 대한 정보를 얻는 속도가 인접 리스트에 비해 훨씬 빠르다. 인접 리스트는 탐색을 통해 확인해야 하지만 인접 행렬은 인덱스로 바로 접근이 가능하기 때문이다.
DFS (Depth-First Search)
DFS는 깊이 우선 탐색이라고도 불리며, 그래프에서 깊은 부분을 우선적으로 탐색하는 알고리즘이다.
DFS는 스택을 이용한다는 점에서 구현이 간단하다. 실제로는 스택을 쓰지 않아도 되며 N개의 데이터를 탐색할 때 O(N)의 시간이 소요된다.
def dfs(graph, v, visited):
# 방문 처리
visited[v] = True
print(v, end=' ')
for i in graph[v]:
if not visited[i]:
dfs(graph, i, visited)
graph = [
[], #노드의 번호가 1 부터라면 0은 비워둠
[2, 3, 8],
[1, 7],
[1, 4, 5],
[3, 5],
[3, 4],
[7],
[2, 6, 8],
[1, 7]
]
visited = [False] * 9
dfs(graph, 1, visited)
# 1 2 7 6 8 3 4 5스택을 사용하지 않아도 구현할 수 있다는 점을 기억하자.
BFS (Breadth First Search)
BFS는 너비 우선 탐색이라고 불리며, 가까운 노드부터 탐색하는 알고리즘이다. DFS가 최대한 멀리 있는 노드부터 탐색하는 반면 BFS는 그 반대라고 할 수 있다.
BFS를 구현할 때는 큐를 이용한다. 인접한 노드를 반복적으로 큐에 넣으면 자연스럽게 먼저 들어온 것이 먼저 나가서 가까운 노드부터 탐색을 한다.
구현 순서
1. 탐색 시작 노드를 큐에 삽입하고 방문 처리한다.
2. 큐에서 노드를 꺼내 해당 노드의 인접 노드 중 방문하지 않은 노드를 모두 큐에 삽입하고 방문 처리한다.
3. 2번의 과정을 계속 진행한다.
from collections import deque
def bfs(graph, start, visited):
queue = deque([start])
visited[start] = True
# 큐가 빌 때까지 반복
while queue:
v = queue.popleft()
print(v, end = ' ')
# 해당 원소와 연결된, 아직 방문하지 않은 원소들을 큐에 삽입
for i in graph[v]:
if not visited[i]:
queue.append(i)
visited[i] = True
# 방문 정보
visited = [False] * 9
graph = [
[],
[2, 3, 8],
[1, 7],
[1, 4, 5],
[3, 5],
[3, 4],
[7],
[2, 6, 8],
[1, 7]
]
bfs(graph, 1, visited)
# 1 2 3 8 7 4 5 6DFS는 재귀 함수를 이용하기 때문에 일반적으로 DFS 보다 BFS가 실제 수행 시간이 좋다.