
이전까지 타깃 데이터를 사용하는 지도 학습에 대해 공부했다. 이번 글에서는 타깃이 없는 데이터를 사용하는 비지도 학습과 대표적인 알고리즘을 공부해보자.
과일을 종류별로 분류하는 문제를 생각해보자. 하나하나 사람이 분류할 수도 없고, 생선처럼 미리 과일 분류기를 훈련하기에는 어떤 과일 사진이 들어올지 알 수 없기 때문에 곤란하다. 사진에 대한 정답(타깃)을 모르는데 어떻게 종류대로 분류할 수 있을까?
비지도 학습 (Unsupervised Learning)
비지도 학습은 타깃이 없을 때 사용하는 머신 러닝 알고리즘이다. 우리가 가르쳐주지 않아도 데이터에있는 무언가를 학습하는 것이다. 위에서 예시로 들었던 과일을 종류별로 분류하는 문제를 연습해보자.
이전에는 csv데이터를 불러와서 모델을 만들었지만 이번에는 넘파이 배열의 기본 저장 포맷인 npy로 되어있는 파일을 불러온다. 넘파이에서 이 파일을 읽으려면 먼저 코랩으로 다운로드해야 한다.
코랩의 코드 셀에서 '!'로 시작하면 코랩은 이후 명령을 파이썬 코드가 아닌 리눅스 셸(shell) 명령으로 이해한다. wget명령은 원격 주소에서 데이터를 다운로드하여 저장해준다. -0 옵션에서 저장할 파일의 이름을 지정할 수 있다.
왼쪽 파일 탭을 열면 아래와 같이 fruits_300.npy가 저장된 것을 볼 수 있다.
numpy와 matplotlib을 이용하여 데이터를 가져오자. npy 파일을 가져올 때는 load() 메서드에 파일 이름만 넣어주면 된다.
fruits의 크기를 확인해보자.

첫 번째 차원(300)은 샘플의 개수, 두 번째 차원(100)은 이미지 높이, 세 번째 차원(100)은 이미지 너비이다. 이미지의 크기는 100 X 100이다. 각 픽셀은 넘파이 배열의 원소 하나에 대응한다. 즉 배열의 크기가 100 X 100이라는 말이다.
첫 번째 이미지의 첫 번째 행을 출력해보자. 3차원 배열이기 때문에 처음 2개의 인덱스를 0으로 지정하고 마지막 인덱스는 지정하지 않거나 슬라이싱을 사용하면 첫 번째 이미지의 첫 번째 행을 모두 선택할 수 있다.

위의 숫자들은 첫 번째 행에 있는 픽셀 100개에 들어 있는 값이다. 이 넘파이 배열은 흑백 사진을 담고 있으므로 0~255까지의 정수 값을 가진다.
맷플롯립의 imshow() 함수는 넘파이 배열로 저장된 이미지를 보여준다. 흑백 이미지이기 때문에 cmap 변수를 'gray'로 지정한다.

그림을 보고 알 수 있듯이 위의 정수들은 0에 가까울수록 어둡고 숫자가 커질수록 밝게 나타난다.
보통 흑백 샘플 이미지는 바탕이 밝고 물체가 짙은 색인데 위의 사진은 반전되어있다. 이 흑백 이미지는 사진으로 찍은 이미지를 넘파이 배열로 변환할 때 반전시킨 것이다. 그렇다면 왜 이렇게 바뀐 것일까?
사진에서 중요한 부분은 사진이지 배경이 아니다. 정수가 0에 가까울수록 어둡고 클수록 밝게 나타난다고 했다. 컴퓨터는 0에 가까운 작은 숫자보다는 큰 숫자에 집중할 것이다. 우리가 보는 것과 컴퓨터가 처리하는 방식이 다르기 때문에 종종 흑백 이미지를 반전하여 사용한다. cmap 변수를 'gray_r'로 지정하면 다시 반전시킬 수 있다.
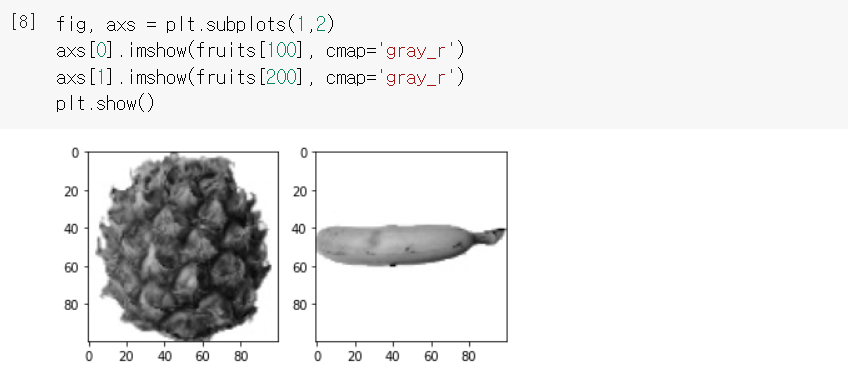
fruits_300에는 사과, 바나나, 파인애플이 각각 100개씩 들어 있다. 바나나와 파인애플도 한번 출력해보자.
맷플롯립의 subplots() 함수는 여러 개의 그래프를 배열처럼 쌓을 수 있도록 해준다. 두 매개변수는 그래프를 쌓을 행과 열을 지정한다.
픽셀 값 분석
픽셀 값을 분석할 때 사용하기 쉽게 각 데이터를 사과, 파인애플, 바나나로 나누고 100 X 100 이미지를 펼쳐서 길이가 10,000인 1차원 배열로 만들자.

각 배열에 들어있는 샘플의 픽셀 평균값을 계산하기 위해 넘파이의 mean() 메서드를 사용해야 한다. 여기서 mean() 메서드는 이전까지 사용했던 np.mean() 함수와는 다르다는 것을 알아두자. mean() 메서드가 평균을 계산할 축을 지정해줘야 하는데 axis=0이면 행, axis=1이면 열을 따라 계산한다. 앞에서 샘플을 1차원 배열로 만들어서 모두 가로로 나열했으니 axis=1로 지정하여 평균을 계산한다.

사과 100개에 대한 픽셀 평균값이다. 히스토그램(Histogram)을 그려보면 평균값을 한눈에 볼 수 있다.
맷플롯립의 hist() 함수를 사용해서 히스토그램을 그릴 수 있다. 각 과일들에 대한 히스토그램을 모두 겹쳐서 그려보자. 그렇게 하려면 투명도를 조절해야 하는데 alpha 변수를 1보다 작게 하면 투명도를 줄일 수 있다. 또 legend() 함수를 사용하면 어떤 과일의 히스토그램인지 범례를 만들 수 있다.
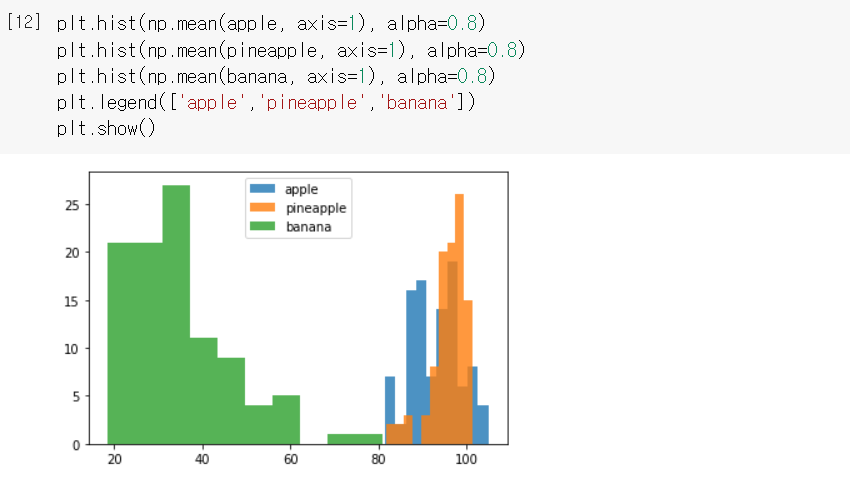
히스토그램을 보면 바나나의 평균값은 다른 두 과일에 비해 작다. 바나는 사진에서 차지하는 영역이 작아 평균값이 작게 나온 것이다.
사과와 파인애플 모두 동그랗고 사진에서 차지하는 비율도 비슷하기 때문에 픽셀 평균값이 비슷하다. 픽셀 전체의 평균값이 아닌 각 픽셀의 평균값을 구해보면 어떨까? 그렇게 하면 특정 위치의 픽셀에 따라 과일이 구분될 수도 있을 것 같다.
각 픽셀의 평균값을 구하려면 axis=0으로 바꾸어 행의 값들을 평균해주면 된다. 이번엔 맷플롯립의 bar() 함수로 픽셀 10000개에 대한 평균값을 막대그래프로 그려보자.
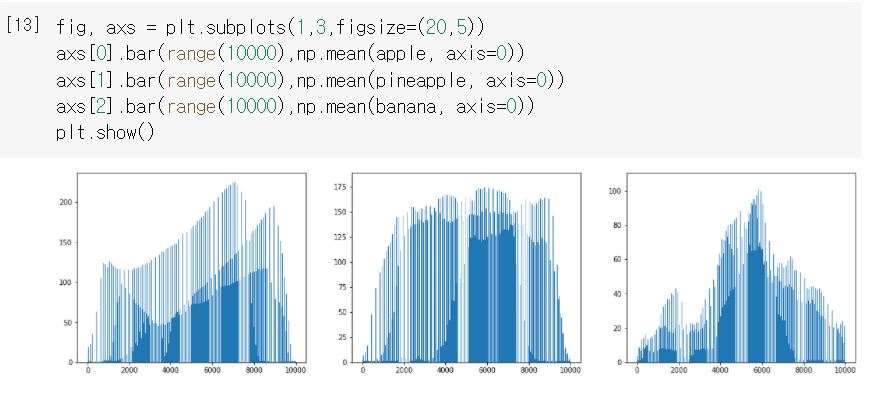
각 과일마다 값이 높은 구간이 다른 것을 확인할 수 있다.
픽셀 평균값을 100 X 100 크기로 바꿔서 이미지처럼 출력해서 비교하면 좋다. 픽셀을 평균 낸 이미지를 모든 사진을 합쳐 놓은 대표 이미지로 생각할 수 있다.

세 과일은 픽셀 위치에 따라 값의 차이가 난다. 이 대표 이미지와 가까운 사진을 골라낸다면 각각의 과일을 구분할 수 있을 것 같다.
평균값과 가까운 사진 고르기
이전에 사용했던 절댓값 오차를 사용해보자. fruits 배열에 있는 모든 샘플에서 apple_mean을 뺀 절댓값의 평균을 계산하면 된다.
절댓값은 abs() 함수는 배열을 받으면 모든 원소의 절댓값을 계산하여 동일한 크기의 배열을 반환한다.

abs_diff는 3차원 배열이기 때문에 평균을 계산해줄 때 두 번째, 세 번째 차원을 모두 지정해줘야 한다. 이렇게 계산한 abs_mean은 각 샘플의 오차 평균이기 때문에 크기가 (300,)인 1차원 배열이다.
그다음 이 값이 가장 작은 순서대로 100개를 골라보자. apple_mean과의 오차가 가장 작은 샘플을 100개 고른다는 말과 같다. np.argsort() 함수는 작은 것에서 큰 순서대로 나열한 abs_mean 배열의 인덱스를 반환한다.


subplots() 함수로 10 X 10 크기의 서브 그래프를 만든다. 전체 그래프의 크기는 figsize를 이용해 조절한다. 기본값은 (8,6)이다. 그다음 2중 for문으로 10개의 행과 열에 이미지를 출력한다. 그리고 axis('off')를 선언하여 좌표축을 그리지 않았다.
이렇게 비슷한 샘플끼리 그룹으로 모으는 작업을 군집(Clustering)이라고 한다. 군집은 대표적인 비지도 학습 작업 중 하나다. 군집 알고리즘에서 만든 그룹을 클러스터(Cluster)라고 한다.
하지만 이미 사과, 파인애플, 바나나가 있다는 것을 알고 있었기 때문에 사과, 파인애플, 바나나의 사진 평균값을 계산해서 가장 가까운 과일을 찾을 수 있었다. 실제 비지도 학습에서는 타깃 값을 모르기 때문에 이처럼 샘플의 평균값을 미리 구할 수 없다. 다음 글에서는 타깃값을 모르면서 세 과일의 평균값을 찾는 법을 k-평균 알고리즘으로 공부해보자.
'AI > 머신 러닝(ML)' 카테고리의 다른 글
| 주성분 분석 (Feat. Dimensionality Reduction) (0) | 2021.09.05 |
|---|---|
| K-평균 알고리즘 (0) | 2021.08.28 |
| 트리의 앙상블 (0) | 2021.08.21 |
| 교차 검증과 그리드 서치(Cross Validation & Grid Search) (0) | 2021.08.18 |
| 결정 트리 (Decision Tree) (0) | 2021.08.16 |
이전까지 타깃 데이터를 사용하는 지도 학습에 대해 공부했다. 이번 글에서는 타깃이 없는 데이터를 사용하는 비지도 학습과 대표적인 알고리즘을 공부해보자.
과일을 종류별로 분류하는 문제를 생각해보자. 하나하나 사람이 분류할 수도 없고, 생선처럼 미리 과일 분류기를 훈련하기에는 어떤 과일 사진이 들어올지 알 수 없기 때문에 곤란하다. 사진에 대한 정답(타깃)을 모르는데 어떻게 종류대로 분류할 수 있을까?
비지도 학습 (Unsupervised Learning)
비지도 학습은 타깃이 없을 때 사용하는 머신 러닝 알고리즘이다. 우리가 가르쳐주지 않아도 데이터에있는 무언가를 학습하는 것이다. 위에서 예시로 들었던 과일을 종류별로 분류하는 문제를 연습해보자.
이전에는 csv데이터를 불러와서 모델을 만들었지만 이번에는 넘파이 배열의 기본 저장 포맷인 npy로 되어있는 파일을 불러온다. 넘파이에서 이 파일을 읽으려면 먼저 코랩으로 다운로드해야 한다.
코랩의 코드 셀에서 '!'로 시작하면 코랩은 이후 명령을 파이썬 코드가 아닌 리눅스 셸(shell) 명령으로 이해한다. wget명령은 원격 주소에서 데이터를 다운로드하여 저장해준다. -0 옵션에서 저장할 파일의 이름을 지정할 수 있다.
왼쪽 파일 탭을 열면 아래와 같이 fruits_300.npy가 저장된 것을 볼 수 있다.
numpy와 matplotlib을 이용하여 데이터를 가져오자. npy 파일을 가져올 때는 load() 메서드에 파일 이름만 넣어주면 된다.
fruits의 크기를 확인해보자.
첫 번째 차원(300)은 샘플의 개수, 두 번째 차원(100)은 이미지 높이, 세 번째 차원(100)은 이미지 너비이다. 이미지의 크기는 100 X 100이다. 각 픽셀은 넘파이 배열의 원소 하나에 대응한다. 즉 배열의 크기가 100 X 100이라는 말이다.
첫 번째 이미지의 첫 번째 행을 출력해보자. 3차원 배열이기 때문에 처음 2개의 인덱스를 0으로 지정하고 마지막 인덱스는 지정하지 않거나 슬라이싱을 사용하면 첫 번째 이미지의 첫 번째 행을 모두 선택할 수 있다.
위의 숫자들은 첫 번째 행에 있는 픽셀 100개에 들어 있는 값이다. 이 넘파이 배열은 흑백 사진을 담고 있으므로 0~255까지의 정수 값을 가진다.
맷플롯립의 imshow() 함수는 넘파이 배열로 저장된 이미지를 보여준다. 흑백 이미지이기 때문에 cmap 변수를 'gray'로 지정한다.
그림을 보고 알 수 있듯이 위의 정수들은 0에 가까울수록 어둡고 숫자가 커질수록 밝게 나타난다.
보통 흑백 샘플 이미지는 바탕이 밝고 물체가 짙은 색인데 위의 사진은 반전되어있다. 이 흑백 이미지는 사진으로 찍은 이미지를 넘파이 배열로 변환할 때 반전시킨 것이다. 그렇다면 왜 이렇게 바뀐 것일까?
사진에서 중요한 부분은 사진이지 배경이 아니다. 정수가 0에 가까울수록 어둡고 클수록 밝게 나타난다고 했다. 컴퓨터는 0에 가까운 작은 숫자보다는 큰 숫자에 집중할 것이다. 우리가 보는 것과 컴퓨터가 처리하는 방식이 다르기 때문에 종종 흑백 이미지를 반전하여 사용한다. cmap 변수를 'gray_r'로 지정하면 다시 반전시킬 수 있다.
fruits_300에는 사과, 바나나, 파인애플이 각각 100개씩 들어 있다. 바나나와 파인애플도 한번 출력해보자.
맷플롯립의 subplots() 함수는 여러 개의 그래프를 배열처럼 쌓을 수 있도록 해준다. 두 매개변수는 그래프를 쌓을 행과 열을 지정한다.
픽셀 값 분석
픽셀 값을 분석할 때 사용하기 쉽게 각 데이터를 사과, 파인애플, 바나나로 나누고 100 X 100 이미지를 펼쳐서 길이가 10,000인 1차원 배열로 만들자.
각 배열에 들어있는 샘플의 픽셀 평균값을 계산하기 위해 넘파이의 mean() 메서드를 사용해야 한다. 여기서 mean() 메서드는 이전까지 사용했던 np.mean() 함수와는 다르다는 것을 알아두자. mean() 메서드가 평균을 계산할 축을 지정해줘야 하는데 axis=0이면 행, axis=1이면 열을 따라 계산한다. 앞에서 샘플을 1차원 배열로 만들어서 모두 가로로 나열했으니 axis=1로 지정하여 평균을 계산한다.
사과 100개에 대한 픽셀 평균값이다. 히스토그램(Histogram)을 그려보면 평균값을 한눈에 볼 수 있다.
맷플롯립의 hist() 함수를 사용해서 히스토그램을 그릴 수 있다. 각 과일들에 대한 히스토그램을 모두 겹쳐서 그려보자. 그렇게 하려면 투명도를 조절해야 하는데 alpha 변수를 1보다 작게 하면 투명도를 줄일 수 있다. 또 legend() 함수를 사용하면 어떤 과일의 히스토그램인지 범례를 만들 수 있다.
히스토그램을 보면 바나나의 평균값은 다른 두 과일에 비해 작다. 바나는 사진에서 차지하는 영역이 작아 평균값이 작게 나온 것이다.
사과와 파인애플 모두 동그랗고 사진에서 차지하는 비율도 비슷하기 때문에 픽셀 평균값이 비슷하다. 픽셀 전체의 평균값이 아닌 각 픽셀의 평균값을 구해보면 어떨까? 그렇게 하면 특정 위치의 픽셀에 따라 과일이 구분될 수도 있을 것 같다.
각 픽셀의 평균값을 구하려면 axis=0으로 바꾸어 행의 값들을 평균해주면 된다. 이번엔 맷플롯립의 bar() 함수로 픽셀 10000개에 대한 평균값을 막대그래프로 그려보자.
각 과일마다 값이 높은 구간이 다른 것을 확인할 수 있다.
픽셀 평균값을 100 X 100 크기로 바꿔서 이미지처럼 출력해서 비교하면 좋다. 픽셀을 평균 낸 이미지를 모든 사진을 합쳐 놓은 대표 이미지로 생각할 수 있다.
세 과일은 픽셀 위치에 따라 값의 차이가 난다. 이 대표 이미지와 가까운 사진을 골라낸다면 각각의 과일을 구분할 수 있을 것 같다.
평균값과 가까운 사진 고르기
이전에 사용했던 절댓값 오차를 사용해보자. fruits 배열에 있는 모든 샘플에서 apple_mean을 뺀 절댓값의 평균을 계산하면 된다.
절댓값은 abs() 함수는 배열을 받으면 모든 원소의 절댓값을 계산하여 동일한 크기의 배열을 반환한다.
abs_diff는 3차원 배열이기 때문에 평균을 계산해줄 때 두 번째, 세 번째 차원을 모두 지정해줘야 한다. 이렇게 계산한 abs_mean은 각 샘플의 오차 평균이기 때문에 크기가 (300,)인 1차원 배열이다.
그다음 이 값이 가장 작은 순서대로 100개를 골라보자. apple_mean과의 오차가 가장 작은 샘플을 100개 고른다는 말과 같다. np.argsort() 함수는 작은 것에서 큰 순서대로 나열한 abs_mean 배열의 인덱스를 반환한다.
subplots() 함수로 10 X 10 크기의 서브 그래프를 만든다. 전체 그래프의 크기는 figsize를 이용해 조절한다. 기본값은 (8,6)이다. 그다음 2중 for문으로 10개의 행과 열에 이미지를 출력한다. 그리고 axis('off')를 선언하여 좌표축을 그리지 않았다.
이렇게 비슷한 샘플끼리 그룹으로 모으는 작업을 군집(Clustering)이라고 한다. 군집은 대표적인 비지도 학습 작업 중 하나다. 군집 알고리즘에서 만든 그룹을 클러스터(Cluster)라고 한다.
하지만 이미 사과, 파인애플, 바나나가 있다는 것을 알고 있었기 때문에 사과, 파인애플, 바나나의 사진 평균값을 계산해서 가장 가까운 과일을 찾을 수 있었다. 실제 비지도 학습에서는 타깃 값을 모르기 때문에 이처럼 샘플의 평균값을 미리 구할 수 없다. 다음 글에서는 타깃값을 모르면서 세 과일의 평균값을 찾는 법을 k-평균 알고리즘으로 공부해보자.
'AI > 머신 러닝(ML)' 카테고리의 다른 글
| 주성분 분석 (Feat. Dimensionality Reduction) (0) | 2021.09.05 |
|---|---|
| K-평균 알고리즘 (0) | 2021.08.28 |
| 트리의 앙상블 (0) | 2021.08.21 |
| 교차 검증과 그리드 서치(Cross Validation & Grid Search) (0) | 2021.08.18 |
| 결정 트리 (Decision Tree) (0) | 2021.08.16 |