
선택 정렬은 매번 가장 작은 것을 선택해서 정렬했다. 선택 정렬은 알고리즘 문제 풀이에 사용하기에는 시간이 매우 오래 걸리기 때문에 다른 접근법이 필요할 듯하다.
삽입 정렬(Insertion Sort)
삽입 정렬은 데이터를 하나씩 확인하여 각 데이터를 적절한 위치에 삽입하는 식으로 정렬을 진행한다.
선택 정렬에 비해 구현 난이도가 높은 편이지만 선택 정렬에 비해 실행 시간 측면에서 더 효율적이다. 특히 삽입 정렬은 필요할 때만 위치를 바꾸기 때문에 데이터가 거의 혹은 완전히 정렬되어있을 때는 매우 효율적이다. 반면에 선택 정렬은 데이터가 완전히 정렬되어있어도 시간 복잡도가 같다.
삽입 정렬은 특정한 데이터가 적절한 위치에 들어가기 전에, 그 앞까지의 데이터는 이미 정렬되어 있다고 가정한다. 정렬되어 있는 데이터 리스트에서 적절한 위치를 찾은 뒤에 그 위치에 삽입된다.
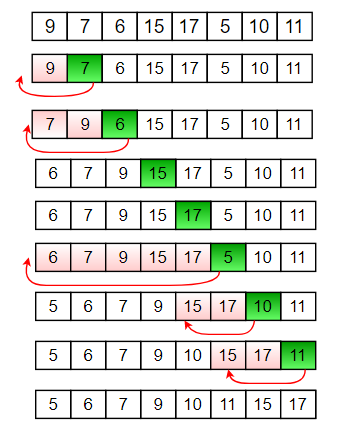
삽입 정렬은 두 번째 데이터부터 비교를 시작한다. 왜냐하면 첫 번째 데이터가 그 자체로 정렬되어 있다고 판단하기 때문이다. 두 번째 데이터부터 앞에 정렬되어 있는 데이터를 비교하면서 자신이 들어갈 위치를 찾아서 삽입된다.
삽입 정렬의 또 하나의 특징은 이미 정렬되어있는 데이터들은 언제나 오름차순으로 정렬되어있다는 것이다. 그러므로 비교할 데이터가 본인보다 작은 데이터를 만나면 그 뒤는 비교해볼 필요도 없이 멈춰서 삽입되면 되는 것이다.
if __name__ == "__main__":
array = [7,5,9,0,3,1,6,2,4,8]
for i in range(1, len(array)):
for j in range(i, 0, -1):
if array[j] < array[j-1]: #한 칸씩 왼쪽으로 이동
array[j], array[j-1] = array[j-1], array[j]
else: #자신보다 비교하는 데이터가 더 작으면
break #비교 정지
print(array)언제나 자신과 자신 전의 데이터와 비교하기 때문에 j와 j-1의 인덱스로 비교를 해주면 된다.
비교 횟수는 앞의 정렬되어있는 개수만큼 비교하여 삽입된다. N개의 데이터가 있다면 1+2+3+...+N-1번 비교하여 삽입된다. 그러므로 시간 복잡도는 O(N²)이다. 직관적으로 for문이 중첩되어 사용됐기 때문이라고 할 수 있다.
time 모듈과 random 모듈을 사용해서 10000개의 난수로 이루어진 array 배열을 정렬하는 데 걸린 시간을 기본 라이브러리의 sort() 메서드와 비교해보자.
##함수 선언 부분##
import time
from random import randint
##변수 선언 부분##
##메인 함수 부분##
if __name__ == "__main__":
##삽입 정렬##
array = []
for _ in range(10000):
array.append(randint(1,100))
start_time = time.time()
for i in range(1, len(array)):
for j in range(i, 0, -1):
if array[j] < array[j-1]: #한 칸씩 왼쪽으로 이동
array[j], array[j-1] = array[j-1], array[j]
else: #자신보다 비교하는 데이터가 더 작으면
break #비교 정지
end_time = time.time()
print("삽입 정렬 성능 측정 :",end_time-start_time)
##기본 라이브러리 sort()##
array = []
for _ in range(10000):
array.append(randint(1, 100))
start_time = time.time()
array.sort()
end_time = time.time()
print("삽입 정렬 성능 측정 :", end_time - start_time)
삽입 정렬은 정렬할 개수가 10000개를 넘어가면 시간이 급진적으로 증가하는 것을 확인할 수 있다.
선택 정렬과 시간 복잡도는 같지만, 현재 리스트의 데이터가 거의 혹은 완전히 정렬되어 있는 상태라면 최선의 경우 O(N)의 시간 복잡도를 가진다는 것이다. 다음에 공부할 퀵 정렬과 비교했을 때, 보통은 삽입 정렬이 느리지만 거의 혹은 완전히 정렬되어 있는 상태라면 퀵 정렬보다 빠른 결과를 낸다.
따라서 거의 정렬되어 있는 상태로 입력이 주어지는 문제라면 다른 정렬 알고리즘보다 삽입 정렬을 이용하는 것이 정답 확률을 높일 수 있다.
추가) 일반적인 경우처럼 배열 안에 정수 한 개나 문자열 한 개인 경우가 아니라 매우 큰 데이터가 담겨있다면, 메모리적으로 선택 정렬이 삽입 정렬보다 좋은 효율을 낸다.
'이코테 > 정렬' 카테고리의 다른 글
| 실전 문제 - 성적이 낮은 순서로 학생 출력하기 (0) | 2021.10.08 |
|---|---|
| 실전 문제 - 위에서 아래로 (0) | 2021.10.08 |
| 계수 정렬 (0) | 2021.09.17 |
| 퀵 정렬 (0) | 2021.09.14 |
| 선택 정렬 (0) | 2021.09.08 |