
퀵 정렬은 삽입 정렬과 선택 정렬에 비해 훨씬 빠른 정렬 알고리즘이고 많이 사용되는 알고리즘이다.
병합 정렬과 함께 대부분의 프로그래밍 언어에서 정렬 라이브러리의 근간이 된다.
퀵 정렬 (Quick Sort)
기본 컨셉은 아래와 같다.
기준 데이터를 설정하고 그 기준보다 큰 데이터와 작은 데이터의 위치를 바꾼다.
퀵 정렬은 기준을 설정한 다음 큰 수와 작은 수를 교환한 후 리스트를 반으로 나누는 방식을 반복한다.
원리만 이해해도 병합 정렬(Merge Sort), 힙 정렬(Heap Sort) 등 다른 고급 정렬 기법에 비해 쉽게 소스코드를 작성할 수 있다.
퀵 정렬에서는 큰 숫자와 작은 숫자를 교환할 때의 기준을 정하는데 이를 피벗(Pivot)이라고 한다.
퀵 정렬을 수행하기 전에는 피벗을 어떻게 설정할 것인지 미리 명시한다. 피벗을 설정하고 리스트를 분할하는 방법에 따라서 여러 가지 방식으로 퀵 정렬을 구분한다. 이 책에서는 그중에 가장 대표적인 분할 방식인 호어 분할(Hoare Partition)방식을 기준으로 퀵 정렬을 설명한다.
호어 분할 방식에서는 리스트에서 첫 번째 데이터를 피벗으로 정한다.
이와 같이 피벗을 설정한 다음엔 왼쪽에서부터 피벗보다 큰 데이터를 찾고, 오른쪽에서부터 피벗보다 작은 데이터를 찾는다. 그다음 큰 데이터와 작은 데이터의 위치를 서로 교환한다. 이러한 과정을 반복하면 피벗에 대하여 정렬이 수행된다.
수행 과정
과정 1

첫 번째 숫자인 5가 피벗이다. 왼쪽부터 5보다 큰 데이터를 선택하므로 7을 선택하고, 오른쪽부터 5보다 작은 데이터를 선택하므로 4를 선택해서 둘을 교환한다.

위와 같은 방식으로 9와 2의 위치를 바꾼다.

같은 방식으로 바꿔주다 보니 왼쪽에서부터 찾는 값과 오른쪽에서부터 찾는 값의 위치가 서로 엇갈린 것을 알 수 있다. 이렇게 두 값이 엇갈린 경우에는 '작은 데이터'와 '피벗'의 위치를 서로 변경한다. 위의 예시에서는 1과 피벗을 바꿔주면 된다.

5의 왼쪽은 모두 5보다 작고, 5의 오른쪽은 모두 5보다 큰 수만 위치하게 정렬이 되었다.
이렇게 피벗의 왼쪽에는 피벗보다 작은 데이터가, 오른쪽에는 피벗보다 큰 데이터가 위치하도록 하는 작업을 분할(Divide) 혹은 파티션(Partition)이라고 한다.
이런 상태에서 왼쪽 리스트와 오른쪽 리스트에서도 각각 피벗을 설정하여 같은 방법으로 정렬하면 전체 리스트가 정렬될 것이다.
과정 2
왼쪽 리스트에서도 과정 1과 같이 진행된다.

4와 0의 위치를 바꾸고, 계속 진행하다가 서로 엇갈리면 피벗과 교환하면 된다.

피벗에 대해서 모두 6보다 크기 때문에 왼쪽 방향은 끝까지 이동하고 오른쪽은 9에서 멈춘다. 작은 데이터와 바꿔야 하므로 6과 바꾸는데 어차피 피벗이기 때문에 바꿔도 변화가 없다.
반복된 작업을 계속 수행하므로 재귀 함수를 이용하면 간결할 것 같다. 또한 리스트의 개수가 1개인 경우에 종료해주면 된다.
다음은 가장 기본이 되는 퀵 정렬의 소스코드이다.
##함수 선언 부분##
def quick_sort(array, start, end):
if start >= end: #원소 개수가 1개인 경우
return
pivot = start #첫 번째 원소가 피벗
left = start + 1
right = end
while left <= right:
#피벗보다 큰 데이터를 찾을 때까지 반복
while left <= end and array[left] <= array[pivot]:
#left가 end보다 커지거나 array[left]값이 피벗보다 큰 값을 찾으면 탈출한다.
left += 1
#피벗보다 작은 데이터를 찾을 때까지 반복
while right > start and array[right] >= array[pivot]:
#right가 피벗과 같거나 작아지거나 array[right]가 피벗보다 작은 값을 찾으면 탈출한다.
right -= 1
if left > right: #엇갈렸다면 작은 데이터와 피벗을 교체한다.
array[right], array[pivot] = array[pivot], array[right]
else: #엇갈리지 않았다면 작은 데이터와 큰 데이터를 교체한다.
array[left], array[right] = array[right], array[left]
#분할 이후 왼쪽 부분과 오른쪽 부분에서 각각 정렬을 수행한다.
quick_sort(array, start, right - 1) #현재 right의 위치에 피벗이 위치한다.
quick_sort(array, right + 1, end)
##변수 선언 부분##
##메인 함수 부분##
if __name__ == "__main__":
array = [5, 7, 9, 0, 3, 1, 6, 2, 4, 8]
quick_sort(array, 0, len(array)-1)
print(array)
위의 코드와 달리 아래의 코드는 파이썬의 장점을 살려 짧게 작성한 퀵 정렬 코드이다.
피벗과 데이터를 비교하는 비교 연산 횟수가 증가하므로 시간 면에서는 조금 비효율적이지만, 더 직관적이고 기억하기 쉽다는 장점이 있다.
##함수 선언 부분##
def quick_sort(array):
#리스트가 하나 이하의 원소만을 담고 있으면 종료
if len(array) <= 1:
return array
pivot = array[0] #첫 번째 원소가 피벗
tail = array[1:] #피벗을 제외한 리스트
left_side = [x for x in tail if x <= pivot] #분할된 왼쪽 부분
right_side = [x for x in tail if x > pivot] #분할된 오른쪽 부분
#분할 이후 왼쪽 부분과 오른쪽 부분에서 각각 정렬을 수행하고, 전체 리스트를 반환
return quick_sort(left_side) + [pivot] + quick_sort(right_side)
##변수 선언 부분##
##메인 함수 부분##
if __name__ == "__main__":
array = [5,7,9,0,3,1,6,2,4,8]
print(quick_sort(array))재귀 함수를 호출할때마다 피벗을 제외한 리스트를 만들어서 정렬하는 방법이다.
시간 복잡도
삽입 정렬이나 선택 정렬의 시간 복잡도는 O(N²)이다. 그에 비해 퀵 정렬의 평균 시간 복잡도는 O(NlogN)이다.
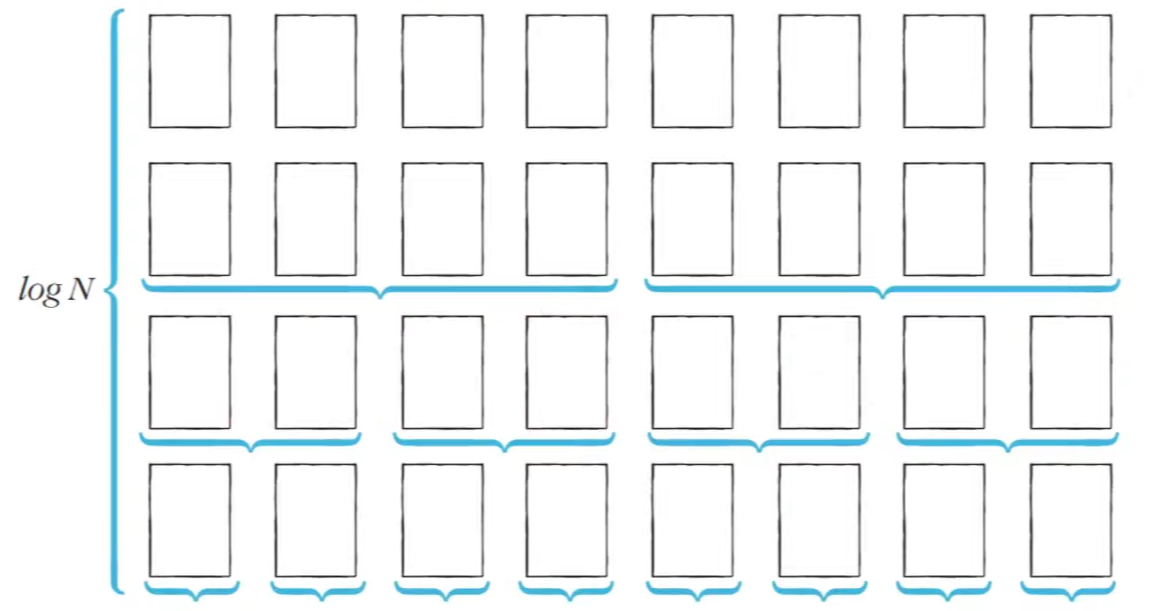
높이가 약 logN이고 너비가 N이기 때문에 O(NlogN)이라고 생각하면 된다.
또 정렬을 하는 횟수가 절반씩 줄어들기 때문에 O(NlogN)이다.
일반적으로 NlogN인 알고리즘들은 대부분 실행 횟수가 절반씩 감소된다고 볼 수 있다.
예를 들어 총 N번을 실행할 것인데, 그 N번중에 첫 번째 실행은 N개의 데이터를 조사하고 그다음엔 N/2개의 데이터를, 그다음엔 N/4개의 데이터를 조사하는 식으로 진행이 된다면 시간 복잡도가 O(NlogN)이다.
'이코테 > 정렬' 카테고리의 다른 글
| 실전 문제 - 성적이 낮은 순서로 학생 출력하기 (0) | 2021.10.08 |
|---|---|
| 실전 문제 - 위에서 아래로 (0) | 2021.10.08 |
| 계수 정렬 (0) | 2021.09.17 |
| 삽입 정렬 (0) | 2021.09.10 |
| 선택 정렬 (0) | 2021.09.08 |